서론
협업 프로젝트를 진행하면서 검색 기능을 구현하는 단계에 들어섰다.
내가 초기 설계 단계에서 설정했던 대로 사용자의 편의성을 높이기 위해 검색 기능과
사용자별 검색 기록을 볼 수 있는 기능을 제공하기로 했으며,
초기 Figma UI를 구현하여 검색 관련 API를 설계 및 구현했다.

초기에는 DB의 LIKE 기능을 이용해 '%키워드%'로 검색하고 사용자별 검색 기록을 저장해 관리하는 방식으로 충분하다고 생각했다.
하지만 추가 요구사항으로 실시간 검색어 및 일일 가장 인기 있는 장소 순위(검색어) 구현이 언급되면서 상황이 달라졌다.

추가 요구사항을 고려해보니, 처음에 계획했던 MySQL의 LIKE 기능을 이용한 '%키워드%' 검색 방식으로는 한계가 있었다.
LIKE는 전체 데이터를 시간대별로 조회하는 풀 스캔 방식이기 때문에, 대량의 데이터를 처리하기에는 비효율적이라고 판단했다.
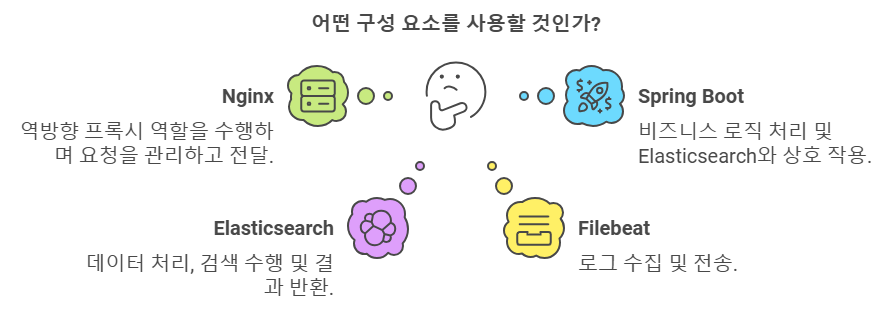
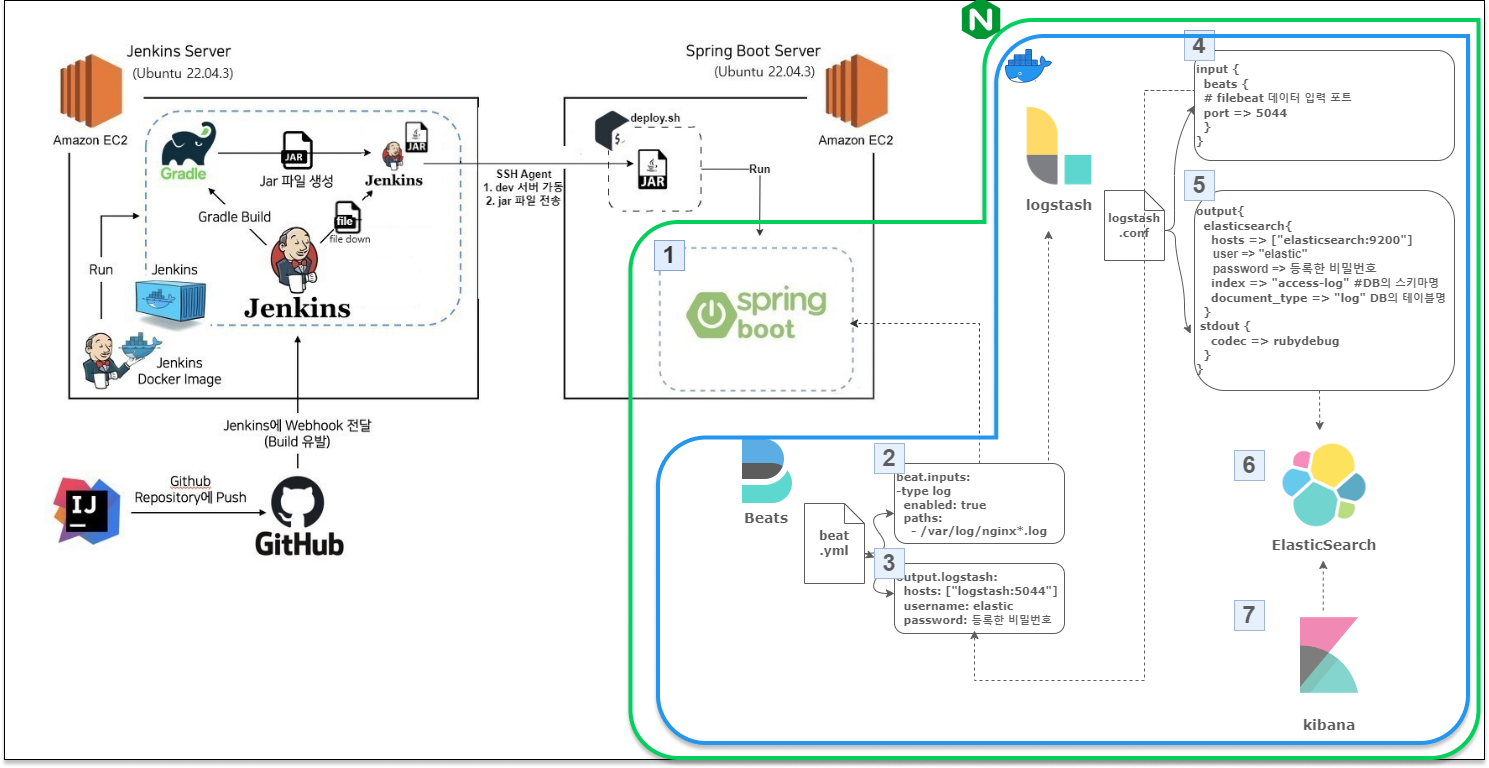
그래서 ELK(Stack)와 Spring Boot, Nginx를 통한 검색 엔진을 도입하여 요구사항을 충족시키는 것이 적절하다고 판단했고,
MySQL과 NoSQL의 읽기/쓰기 성능을 비교하여 진행 중인 프로젝트에 ELK를 도입한 과정을 정리하게 되었다.
프로젝트 설정
docker-compose.yml
version: '3.7'
services:
nginx:
image: nginx:latest
container_name: nginx
ports:
- "80:80"
volumes:
- ./nginx.conf:/etc/nginx/nginx.conf:ro
networks:
- es-bridge
depends_on:
- kibana
elasticsearch:
build:
context: .
args:
VERSION: 7.17.3
container_name: elasticsearch
environment:
- node.name=single-node
- cluster.name=backtony
- discovery.type=single-node
- xpack.security.enabled=true
- xpack.security.authc.realms.native1.type=native
- xpack.security.authc.realms.native1.order=0
- http.cors.enabled=true
- http.cors.allow-origin="*"
- ELASTIC_PASSWORD=cobi1234
ports:
- "9200:9200"
- "9300:9300"
networks:
- es-bridge
volumes:
- esdata:/usr/share/elasticsearch/data
logstash:
image: docker.elastic.co/logstash/logstash:7.17.3
container_name: logstash
volumes:
- ./logstash.yml:/usr/share/logstash/config/logstash.yml
- ./logstash.conf:/usr/share/logstash/pipeline/logstash.conf
ports:
- "5044:5044"
networks:
- es-bridge
depends_on:
- elasticsearch
kibana:
image: docker.elastic.co/kibana/kibana:7.17.3
container_name: kibana
environment:
- ELASTICSEARCH_HOSTS=http://elasticsearch:9200
- ELASTICSEARCH_USERNAME=elastic
- ELASTICSEARCH_PASSWORD=cobi1234
ports:
- "5601:5601"
networks:
- es-bridge
depends_on:
- elasticsearch
filebeat:
image: docker.elastic.co/beats/filebeat:7.17.3
volumes:
- ./filebeat.yml:/usr/share/filebeat/filebeat.yml:ro
- /var/log/nginx:/var/log/nginx:ro
networks:
- es-bridge
depends_on:
- logstash
networks:
es-bridge:
name: es-bridge
volumes:
esdata:
driver: local
프로젝트 설정 docker-compose.yml 진행 중이던 docker-compose.yml에 추가 설정을 진행했다.
여기서 중요한 점은 다음과 같다:
- ElasticSearch에서 6.8.0과 7.1.0부터 기본적으로 X-Pack Security 기능이 포함되어 무료로 제공되기 시작되기 때문에 추가적으로 보안 설정을 진행해야 한다
- elk의 모든 서비스가 es-bridge라는 네트워크에 속해야 한다는 점
- elasticsearch의 데이터 손실을 방지하기 위해 volume을 사용한다는 점
실제로 진행하면서 가장 많이 겪은 오류는 401 권한 오류였다.
Spring Boot와 ELK 간 통신에서 발생한 권한 문제가 많았고, Spring Security를 사용하는 경우 http.authorizeRequests()로 Elasticsearch 요청을 허용해야 한다.
Dockerfile
Elasticsearch에는 한국어 형태소 분석기가 포함되어 있지 않기 때문에,
한국어 텍스트 처리 기능을 추가로 설정해줘야 하는데 그를 위해 nori라는 한국어 형태소 분석 플러그인을 설치해야 한다.
Nori는 한국어의 복잡한 어미와 접사 처리, 형태소 기반 토큰화 등을 지원하여 정확한 검색 결과를 제공하는 데 사용되며 한국어 처리의 검색 성능을 만들어 주기 때문에 필수적인 작업이라고 할 수 있다.
따라서 Docker 이미지를 빌드할 때 특정 버전의 Elasticsearch를 사용할 수 있도록 설정해 놓는다.
ARG VERSION
FROM docker.elastic.co/elasticsearch/elasticsearch:${VERSION}
RUN elasticsearch-plugin install analysis-nori
이후 Docker를 실행하고, 버전이 6.8.0 이상이라면 기본 계정에 패스워드를 설정해야 한다.
이를위해 elasticsearch 클러스터 노드에 접속하고
elasticsearch-setup-passwords interactive명령어를 실행하면, elastic, kibana, logstash_system, beats_system를 설정할 수 있으며, 나는 동일한 비밀번호로 저장을 진행하였다.
이후 포트를 각각 접속하면 ( 9200, 5601 ) elasitcsearch, kibana 창이 나온다면 성공적으로 설정은 마무리되었고,
username과 password를 입력란에 이것은 `elastic` 비밀번호는 위의 패스워드가 되면 정상적으로 접속될 것이다.
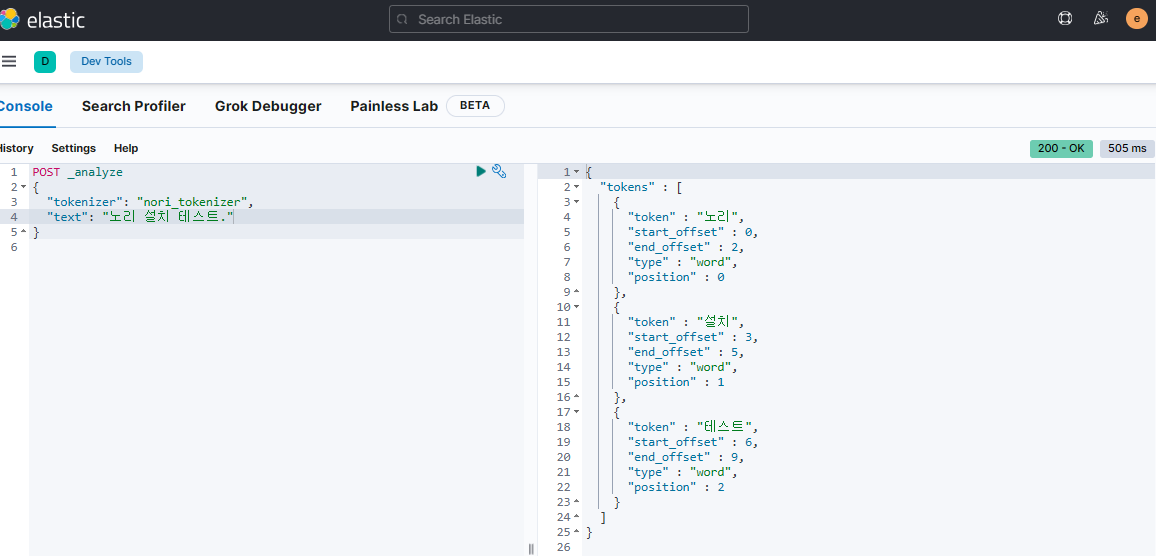
nori 플러그인까지 정상적으로 처리됨을 확인하려면
키바나(5601)의 console로 이동하여 한국어 처리가 됨을 알 수 있다.
Spring설정
Spring에서는 순차적으로 설정을 진행하면 Elasticsearch와 정상적으로 연결된다.
중요한 것은 프로젝트의 환경 설정이다.
Spring Security를 사용하거나 SSL/TLS 환경에서 사용하는 경우,
Elasticsearch의 버전이 6.8.0 및 7.1.0 이상이라면 추가적인 인증 설정이 필요하다.
필자는 Spring Security + http 환경 + Windows + Elasticsearch 7.17.3 버전 기준으로 작성되었다.
ElasticConfig 설정을 통해 RestHighLevelClient로 클라이언트 작업 및 연결을 설정하고,
Elasticsearch 연동 도메인, 인덱스 매핑 파일(JSON), Nori를 통한 한국어 처리 등을 진행했다.
이후 ElasticsearchRepository 인터페이스를 상속받아서 사용하면 되는데 JPA에서 익숙한 리포지토리 형태로 간단한 작업은 모두 지원이 되어 쉽게 사용할 수 있었다.
Repository의 상세한 내용은 해당 링크에서 확인하면 다양하게 활용할 수 있을 것 같다.
build.gradle
// spring boot log to elastic search
implementation 'com.internetitem:logback-elasticsearch-appender:1.6'
implementation 'dev.akkinoc.spring.boot:logback-access-spring-boot-starter:3.2.1'
...ElasticSearchConfig
package com.project.always.bar.elasticsearch.util;
import com.project.always.bar.elasticsearch.repository.BarSearchRepository;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.elasticsearch.client.ClientConfiguration;
import org.springframework.data.elasticsearch.client.RestClients;
import org.springframework.data.elasticsearch.repository.config.EnableElasticsearchRepositories;
@EnableElasticsearchRepositories(basePackageClasses = BarSearchRepository.class)
@Configuration
public class ElasticSearchConfig extends AbstractElasticsearchConfiguration {
@Override
public RestHighLevelClient elasticsearchClient() {
ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo("localhost:9200")
.withBasicAuth("elastic", "cobi1234")
.build();
return RestClients.create(clientConfiguration).rest();
}
}
AbstractElasticsearchConfiguration
package com.project.always.bar.elasticsearch.util;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.data.elasticsearch.config.ElasticsearchConfigurationSupport;
import org.springframework.data.elasticsearch.core.ElasticsearchOperations;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.data.elasticsearch.core.convert.ElasticsearchConverter;
public abstract class AbstractElasticsearchConfiguration extends ElasticsearchConfigurationSupport {
@Bean
public abstract RestHighLevelClient elasticsearchClient();
@Bean(name = { "elasticsearchOperations", "elasticsearchTemplate" })
public ElasticsearchOperations elasticsearchOperations(ElasticsearchConverter elasticsearchConverter,
RestHighLevelClient elasticsearchClient) {
ElasticsearchRestTemplate template = new ElasticsearchRestTemplate(elasticsearchClient, elasticsearchConverter);
template.setRefreshPolicy(refreshPolicy());
return template;
}
}ProjectApplication
package com.project.always;
import com.project.always.bar.elasticsearch.repository.BarSearchRepository;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.FilterType;
import org.springframework.data.jpa.repository.config.EnableJpaRepositories;
@EnableJpaRepositories(excludeFilters = @ComponentScan.Filter(
type = FilterType.ASSIGNABLE_TYPE,
classes = BarSearchRepository.class))
@SpringBootApplication
public class AlwaysApplication {
public static void main(String[] args) {
SpringApplication.run(AlwaysApplication.class, args);
}
}
특정 도메인
package com.project.always.bar.elasticsearch.domain;
import com.project.always.bar.dto.BarDTO;
import java.time.LocalDateTime;
import javax.persistence.*;
import lombok.AccessLevel;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Getter;
import lombok.NoArgsConstructor;
import org.springframework.data.elasticsearch.annotations.DateFormat;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import org.springframework.data.elasticsearch.annotations.Mapping;
import org.springframework.data.elasticsearch.annotations.Setting;
@Getter
@AllArgsConstructor
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Document(indexName = "bar")
@Mapping(mappingPath = "elastic/bar-mapping.json")
@Setting(settingPath = "elastic/bar-setting.json")
public class BarDocument {
@Id
@Field(type = FieldType.Keyword)
private Long id; //술집번호
@Field(type = FieldType.Text)
private String title;
@Field(type = FieldType.Text)
private String location; //술집위치
@Field(type = FieldType.Text)
private String image; //대표이미지
@Field(type = FieldType.Text)
private String tel; //전화번호
@Field(type = FieldType.Double)
private Double rating;//술집 평점
@Field(type = FieldType.Date, format = {DateFormat.date_hour_minute_second_millis, DateFormat.epoch_millis})
private LocalDateTime startDate;
@Builder
private BarDocument(Long id, String title, String location, String image, LocalDateTime startDate,
LocalDateTime endDate,
String tel, Double rating) {
this.id = id;
this.title = title;
this.location = location;
this.image = image;
this.startDate = startDate;
this.tel = tel;
this.rating = rating;
}
public static BarDocument of(BarDTO dto) {
return BarDocument.builder()
.id(dto.getId())
.title(dto.getTitle())
.location(dto.getLocation())
.image(dto.getImage())
.startDate(LocalDateTime.now())
.endDate(LocalDateTime.now())
.tel(dto.getTel())
.rating(dto.getRating())
.build();
}
}
SearchRepository
package com.project.always.bar.elasticsearch.repository;
import com.project.always.bar.elasticsearch.domain.BarDocument;
import java.util.List;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
public interface BarSearchRepository extends ElasticsearchRepository<BarDocument, Long> {
List<BarDocument> findByTitle(String title);
List<BarDocument> findByLocation(String location);
}bar-mapping.json
{
"properties" : {
"id" : {
"type" : "keyword"},
"title" : {
"type" : "text",
"analyzer" : "korean"},
"location" : {
"type" : "text",
"analyzer" : "korean"},
"image" : {
"type" : "text"},
"tel" : {
"type" : "text"},
"rating" : {
"type" : "double"},
"startDate" : {
"type" : "date",
"format": "uuuu-MM-dd'T'HH:mm:ss.SSS||epoch_millis"}
}
}bar-setting.json
{
"analysis": {
"analyzer": {
"korean": {
"type": "nori"
}
}
}
}
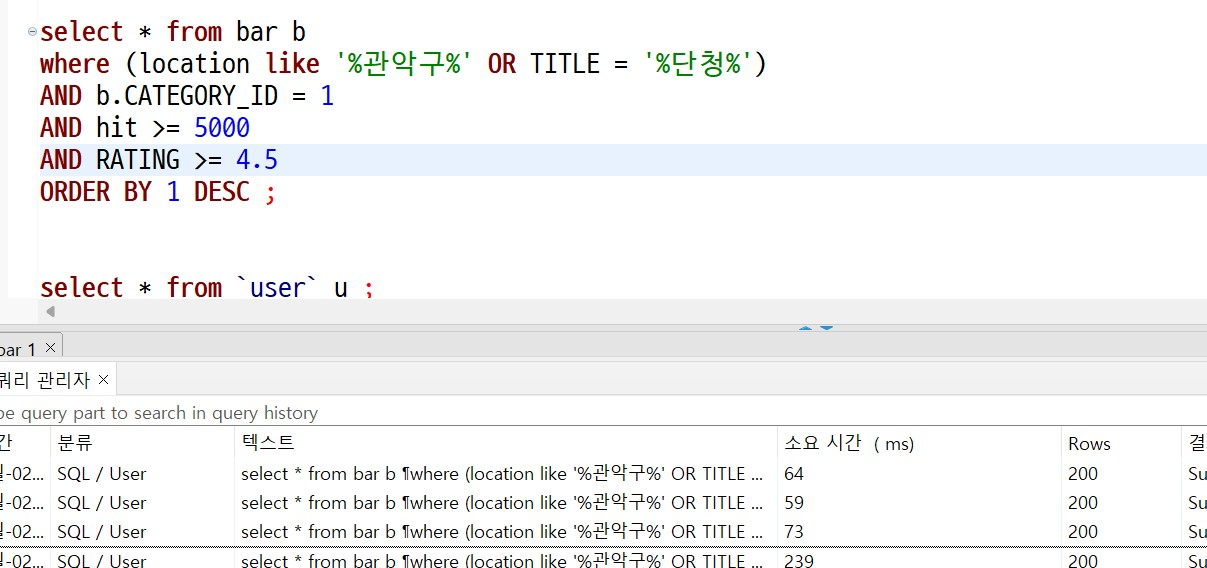
Mysql vs ELK 처리 읽기 쓰기 비교
- 쓰기 성능

데이터 쓰기의 경우 기존 시스템에 만 건의 데이터를 추가하는 방식으로 테스트한 결과,
MySQL은 약 204,207ms(약 3분 24초) 걸렸고, ELK는 65초가 걸렸다.
쓰기의 경우에는 큰 차이가 없거나 mysql이 쓰기에서는 더 성능적으로 우수하다고 판단했지만
약 68.2%의 성능 개선이 이루어졌는데 설정이 올바른지 추가 확인이 필요하다.
- 읽기 성능
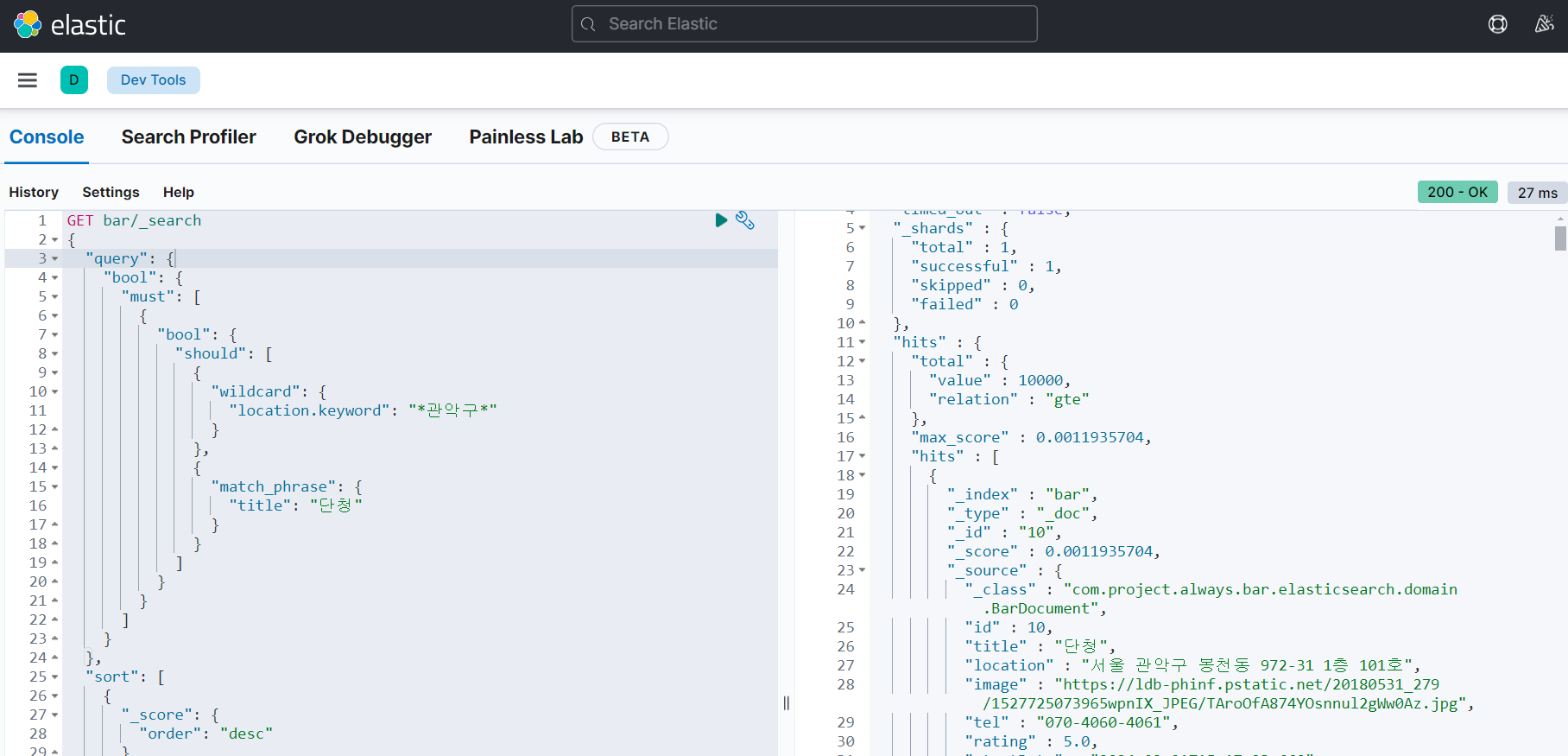
조회 성능의 경우 데이터 크기와 네트워크 상태를 제외하고
단순하게 비교했을 때 처음 db 쿼리를 조회하는 기준 Rdms는 239ms, kibana Console은 27ms
데이터 양이 적은 것에 비해 검색 성능에서 약 88.7%의 성능 개선이 이루어짐을 알 수 있다.
이는 데이터가 많아질수록 ELK의 검색 성능은 더욱 두드러질 것이고, 비정형 데이터의 모델의 이점도 활용할 수 있을 것이다.
Mysql (RDMS) vs ElasticSearch (Nosql) 정리
| 특징 | MYSQL (RDBMS) | Elasticsearch (NoSQL) |
| 읽기 처리 속도 | - 고정된 구조에서 인덱스를 적절히 사용하면 빠름. 특히 트랜잭션 및 일관성 요구 시 우수. |
- 대량의 텍스트 데이터나 로그 데이터를 빠르게 검색 가능 (역색인 방식 사용). |
| 인덱스 없는 경우 테이블 스캔 발생으로 느려질 수 있음. | - 복잡한 쿼리에서 성능 저하 가능성 있음 (특히 집계 연산 시), 하지만 분산 처리를 통해 보완. |
|
| 쓰기 처리 속도 | - 트랜잭션 보장을 위해 쓰기 작업이 느릴 수 있음. | - 대량 쓰기가 필요할 때 성능이 우수하지만, 일관성을 보장하는 데 추가적인 설정 필요. |
| - 다중 테이블 간의 관계와 제약 조건이 있는 경우 성능 저하. |
- 실시간 쓰기 및 분석에 최적화됨. 비정형 데이터를 처리하는 데 매우 빠름. | |
| 데이터 모델 | 관계형 모델(스키마 기반)로 데이터 무결성 보장. | - 비정형 데이터에 적합한 유연한 스키마로, 데이터의 형태가 자주 변경되는 경우 유리. |
| 실시간 데이터 처리 |
트랜잭션 처리에 유리하나 실시간 검색이나 로그 분석에 부적합할 수 있음. | - 실시간 검색 및 분석에 뛰어남, 특히 대규모 로그 데이터 처리 시 적합. |
| 데이터 저장 방식 | 관계형 테이블 기반. 스키마가 고정되어 있어 스키마 변경 시 성능에 영향이 있을 수 있음. |
- 문서 기반(NoSQL), 스키마리스. 자유롭게 필드를 추가하거나 제거 가능, 유연성이 높음. |
RDBMS와 NoSQL의 차이를 확인한 결과, 검색 엔진을 활용하는 것이 추가 요구사항에 더 적합하다는 결론을 내렸다.
정리하자면, 요구사항을 충족시키기 위해 ELK 스택을 도입한 것이 적절하다고 판단했다.
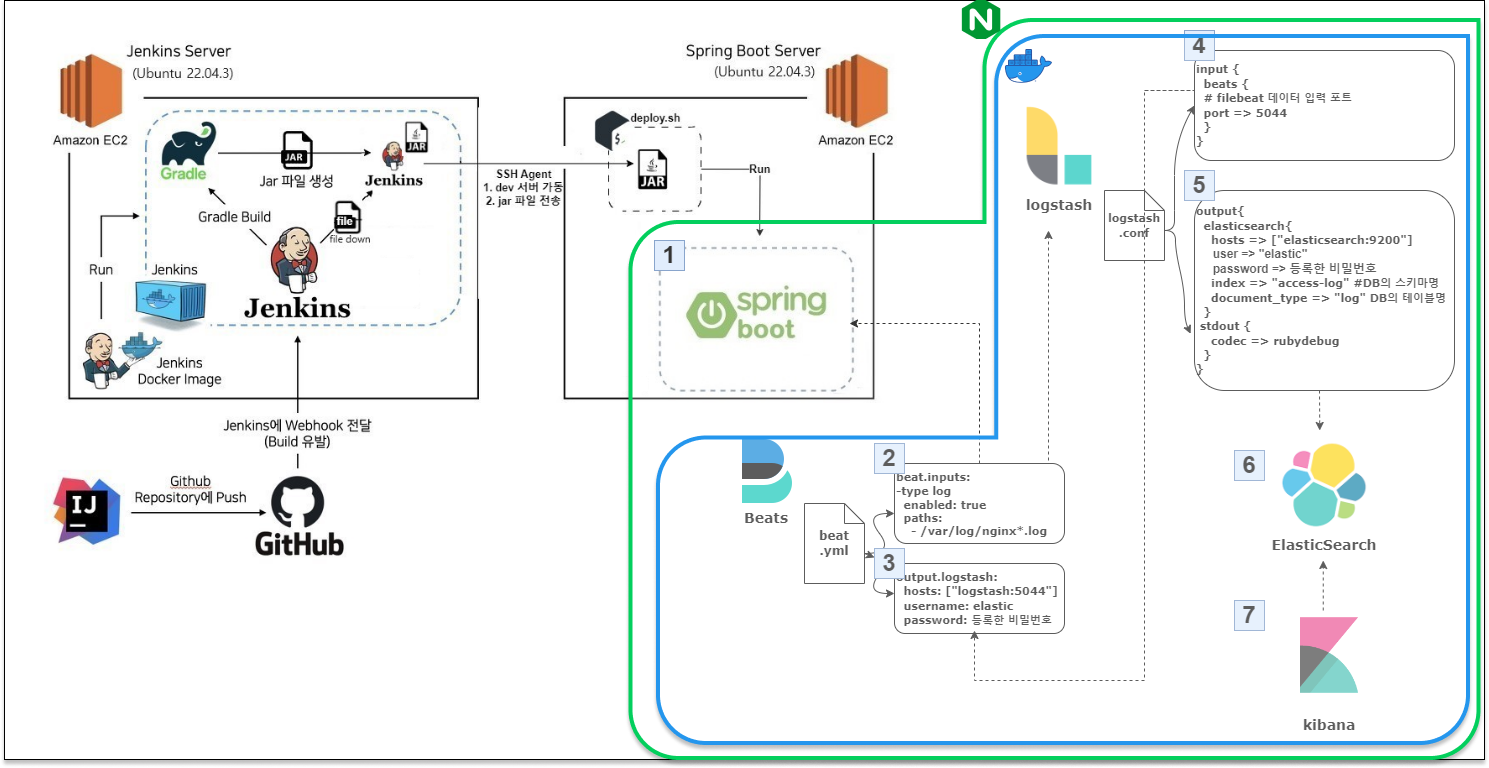
다음 포스팅에서는 기존 프로젝트에 ELK 스택(Elasticsearch, Logstash, Kibana)을 추가하여 시스템 아키텍처가 어떻게 개선되었는지, 다음과 같은 구조로 구축된 내용을 자세히 다룰 예정이다
Reference
https://spring.io/projects/spring-data-elasticsearch
Spring Data Elasticsearch
Spring Data for Elasticsearch is part of the umbrella Spring Data project which aims to provide a familiar and consistent Spring-based programming model for for new datastores while retaining store-specific features and capabilities. The Spring Data Elasti
spring.io
https://tecoble.techcourse.co.kr/post/2021-10-19-elasticsearch/
Spring Data Elasticsearch 설정 및 검색 기능 구현
실습 Repository에서 코드를 확인할 수 있습니다. 1. Elasticsearch Elasticsearch는 Apache Lucene 기반의 Java 오픈소스 분산형 RESTful…
tecoble.techcourse.co.kr
'Project > 협업프로젝트' 카테고리의 다른 글
| [협업프로젝트] Jenkins와 Docker로 CI/CD pipeline 구축하기 (2) (2) | 2023.10.31 |
|---|---|
| [협업프로젝트] Jenkins와 Docker로 CI/CD pipeline 구축하기 (1) (0) | 2023.10.30 |
| [협업프로젝트] SpringBoot 프로젝트 EC2, RDS 적용 (0) | 2023.10.30 |
| [협업프로젝트] SpringBoot 프로젝트 EC2 배포하기 (1) | 2023.10.29 |
| [협업프로젝트] SwaggerUI + Spring RestDocs 로 API 문서화하기 (2) | 2023.10.14 |